

A PDF version of this overly long post is available here .
I should begin with a disclaimer: I am not a Sanskritist. I took a couple of years of compulsory Sanskrit in middle school, was bored witless by the rote memorization of verb conjugations and by the anodyne assigned texts, and so ran away from the language as soon as I was afforded an opportunity. A lifetime of reading pre-modern Indian texts in translation, many of them tantalizingly dazzling even in English and Hindi, has led me to back to Sanskrit, and so for some years I’ve worked with a tutor between teaching and writing and parenting. For the past few months, with the infinitely patient help of my teacher, I’ve been struggling through the Paṇcatantra (“Five Treatises,” circa 300 BCE), a collection of dark, didactic tales about realpolitik and effective action. The stories are written in elegant but simple Sanskrit considered suitable for the beginner, but that is as far as my proficiency extends. So you must think of me as a sort of analogue to the popularizing science reporter who brings the research of actual specialists to a large lay audience. My thanks to Dr. Satyam Dwivedi and Sanhita Joshi for their help and many contributions; any mistakes in what follows are entirely mine.
The transliteration scheme used here is the International Alphabet of Sanskrit Transliteration (IAST), which allows for the lossless Romanization of Sanskrit and related Indic scripts. For a pronunciation guide, see here.
*
The earliest Sanskrit texts that we have available are the Vedas, the oldest of which – the Rig Veda – is dated to approximately 2000-1700 BCE.[1] The Vedas are believed to be apauruṣeya – uncreated, authorless, and self-validating. To make an analogy, the code that creates and sustains the universe exists as a constant, ever-present cosmic hum. Certain wise and spiritually-advanced men and women, the rishis, are able to hear this eternal knowledge – encoded in indestructible phonemes – and transmit it to human beings as the hymns of the Vedas. The Vedas are therefore śruti, “that which is heard,” revealed to the rishis in visions, and are therefore the highest form of sacred knowledge. Other texts, like the Rāmāyana and the Mahābhārata, are also sacred, but they are only smṛti, “remembered,” and therefore spring from acts of human authorship, with all the possibility of error and contradiction such authorship entails. The Vedas are a direct transmission from the Source, and that eternal reality is the eternal Word, śabda-brahman, transcendental sound.[2]
The social and religious society shaped by the Vedas was and is centred around sacrifice, yajña. Oblations are poured into the sacred fire, agni, as the Vedic hymns are chanted. The scale of some Vedic sacrificial rites is immense. The ancient Agnicayana (“the piling of the fire-altar”) ritual is a “a ritual recreation of the original sacrifice of the cosmic man (Puruṣa/Prajāpati), through which the universe was created and ordered, and his re-ordering to ensure the continuity of the seasons and the well-being of the sacrificer.”[3] The Agnicayana requires up to a year of preparation; the main altar is made of as many as10,800 bricks placed in five layers in a prescribed sequence, with each brick representing an aspect of the universe in a homologous fashion and requiring specific mantras and actions to accompany its laying; seventeen priests of different types are required to perform the ritual.[4] A compressed version of the rite – filmed by Frits Staal in 1975 – took twelve days to complete. This ritual required – among many other materials – 14 ½ grams of gold and 14 live goats (which were finally not sacrificed due to contemporary sensibilities; they were replaced by rice flour folded in banana leaf).[5] Within the main east-facing Great Altar or mahavedi, a five-layered brick altar is constructed in the form of a bird of prey, a falcon, śyena.[6] Figure 1 shows the order of the bricks in the first layer of the śyena citi, the falcon-shaped altar used in the 1975 sacrifice.[7]
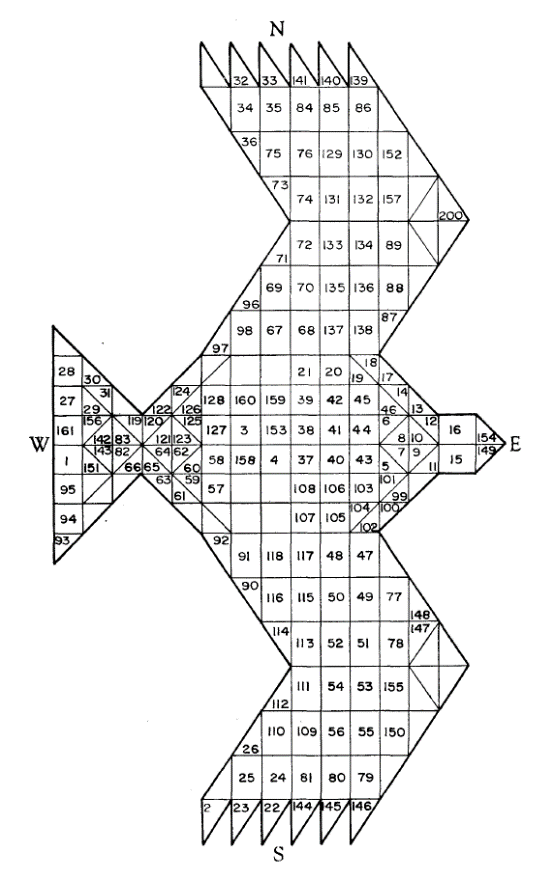
One such altar, excavated in the Uttarakhand district of the central Himalayas, is thought to date to some time between the 1st century BCE and the 2nd century CE; it measures 78.7 by 59 feet (Figure 2).[8]

But a Vedic sacrifice is not just an occasion to offer gifts to the divine, because in the Vedic universe, “all elements of the universe, human and divine, are interconnected and interdependent. For this reason, everything that happens in the sacrifice is analogous to both individual and cosmic processes.”[9] By engaging in a yajña, the patron of the sacrifice may gain in this world, but he is also reconstructing and regenerating the universe itself, because to chant the Vedic hymns during a properly-run yajña is to engage directly with the cosmic code itself. As David Shulman puts it, “Anyone who reads the descriptions (or, rather, the operating instructions) will see at once that the altar, painstakingly built up of 10,800 bricks of specified types, is a full-scale model of the cosmos in all its parts and pieces; the text also tells us clearly which layers of the altar are to be equated with which cosmic level, to say nothing of the large set of esoteric equivalences that identify the roles of individual bricks or implements.”[10]
Despite the colossal complexity of this physical model and its associated costs in human effort and wealth – surely that Purola altar was part of a royal sacrifice – the same text that treats the Agnicayana ritual in most detail, the Śatapatha Brāhmana (“Commentary of One Hundred Paths,” 1000 – 700 BCE), tells us in no uncertain terms, “All the rituals performed in the sacrifice, all that are linked to the rite, all this was performed in and by Speech on what was speech-made and speech-gathered, and consisted only of Speech.”[11] The verbalized, chanted hymns, therefore, are what energize and mobilize the efficacy of the sacrifice. It is speech, sacred sound, sometimes personified as the goddess Vāk, that is the supreme creative and sustaining power of the universe; the divine energy of the Vedas lies not only in the meaning of the words, but in the metres, the pitch, the tonality of each syllable. A single error during recitation could turn the awesome powers set in motion by the sacrifice against the sacrificer. And it is also crucially important that the hymns of the Vedas be passed down from rishi to layperson and then through generation after generation without linguistic or aural deviation, without slippage of any sort whatsoever.
The ancient Indian linguists came up with sophisticated oral error-checking methods to assure correct recitation and transmission. As Pierre-Sylvain Filliozat observes, “In later times, even when writing became a common practice, [this error-checking scheme] was not forgotten, nor neglected. It is still practiced in modern times. It is the profession of a few Brahmans who retain its antic form and still refuse to use the help of writing and other tools offered by modern technology. It is a very elaborate art. It includes eleven modes of recitation of the same text. One purpose of this multiplication is the conservation of the text: if a mistake is committed in one recitation, without being repeated in another, comparison between the two recitations helps to detect and to correct it.”[12]
The simplest form of recitation is the standard “continuous recitation,” saṃhitā-pāṭha. So a verse might run:
devīṃ vācamajanayanta devāstāṃ viśvarūpāḥ paśavo vadanti |
sā no mandreṣamūrjaṃ duhānā dhenurvāgasmānupa suṣṭutaitu ||
Gods engendered the goddess Speech. Creatures of all forms speak her. May this amiable Speech, a cow giving her milk of force and vitality, well-praised, come to us.[13]
In another form of recitation, krama-pāṭha, “recitation step by step,” any words which have been combined according to the rules of sandhi (sound changes and euphonic combination, as in the English “I would” becoming “I’d”) are broken up, and then all the words are repeated in a “ab / bc / cd” pattern, so that the above verse becomes:
Devīm vācam / vācam ajanayanta / ajanayanta devāḥ / devas tam / tām viśvarūpaḥ / viśvarūpaḥ paśvaḥ / viśvarūpā iti viśva-rūpāh / paśavo vadanti / vadantīti vadanti / ūpa suṣṭutā / suṣṭutā / suṣṭutaitu / suṣṭuteti su-stutā / aitu / evt iti etu
The next form, jaṭā-pāṭha, “recitation in the form of meshes,” takes “a pair of words from the krama-pāṭha, repeats it in reverse order, then in the original order, and then goes on to the next pair, up to the end of a stanza: ab, ba, ab; bc, cb, bc;…”[14] And so on through a number of other forms until the most complex, the ghana-pātha, “dense recitation,” which “takes a pair, reverses it, takes it again with the addition of a third word, reverses the sequence of the three words, repeats them in their original order, goes to the next pair, and so on up to the end of the stanza: ab ba abc cba abc; bc cb bcd dcb bcd;…”[15] So in ghana-pātha, the beginning of our verse would become:
devīm vācaṃ vācaṃ devīm devīm vācam ajanayantājanayanta vācaṃ devīm devīm vācam ajanayanta…
To see a recent ghana-pātha recitation, click here.
Filliozat concludes his discussion of these error-checking schemes by observing that the Rig Veda, “which is the most ancient Indian text, has been preserved without variant readings. These techniques have ensured the conservation of the form of the text.”[16]
I hope I have conveyed, with the discussion above, a short portrait of a culture singularly obsessed with language and its workings. It is this long-established intellectual and scientific milieu that engenders Pāṇini’s astonishing work, which we will soon encounter. But I cannot resist one aside: if you are an orthodox Vedic believer, a follower of the very early Pūrva Mīmāṃsā or “First Reflection” school of Indian philosophy, you are by definition an atheist (although not a materialist). There are gods in the Vedas, but these devas, “the shining ones,” are not the psychologically-developed human-seeming personas of later theistic Hinduism or the Greek pantheon; they seem more like fuzzy, suggestive coalescings of eternal principles; Agni, the fire; Sūrya, the sun; Vāyu, the wind. And in the cosmology of the Mīmāṃsā, there is no creator god, no First Cause, because that would require this creator to be superior to the universal Vedic code. And that cannot be, because the code is supreme. The code just is. The code does not care if you obey its injunctions or not. The code just runs. The Vedas have therefore been the backdrop for popular theistic Hinduism through the centuries, but they also gave rise to the robust traditions of atheism and hard-headed scepticism that have also always existed within the Indic mainstream.
*
The prodigious intellectual resources applied to the preservation and study of the Vedas over the centuries gave rise to six auxiliary disciplines, the vedaṅga, “the limbs of the Veda”:
- jyotiṣa, astronomy
- kalpa, ritual
- śikṣa, phoenetics
- chandas, metre
- vyākaraṇa, grammar
- nirukta, etymology
Notice that four out of these six disciplines are focussed on language; it has also been argued that the discipline of kalpa, ritual, prescribed meticulous altar geometries requiring transformations of plane figures, etc., and thus gave rise to Indian mathematics.
A linguist named Pāṇini created a revolution in the domain of grammar, vyākaraṇa, by publishing a very small text titled Aṣṭādhyāyī, “The Eight Chapters”; the date for this epochal event is contested – general consensus places it at around 500 BCE; some Indian scholars argue for an earlier date, perhaps around the 7th century BCE.[17] Pāṇini’s book is generally described as a “grammar,” but it is certainly not a grammar in the traditional English sense of the word. Rather, as S. D. Joshi puts it, “It is a device, a derivational word-generating device… It derives an infinite number of correct Sanskrit words, even though we lack the means to check whether the words derived form part of actual usage. As later grammarians put it, we are lakṣaṇaikacakṣuṣka, solely guided by rules. Correctness is guaranteed by the correct application of rules.”[18]
The Aṣṭādhyāyī comprises 3976 rules in the form of sūtras; most of the rules are just two or three words long, as we can see below in the short listing from Chapter 1.
1.1.46 ādyantau ṭakitau
1.1.47 midaco’ nīyāt paraḥ
1.1.48 ec ig hrasvādeśe
1.1.49 şaşṭḥī sthāne yogā[19]
The rules of the Aṣṭādhyāyī work in conjunction with some essential auxiliary texts.
The Śivasūtras (also Akṣarasamāmnāya, “Recitation of phonemes”) are the first of these auxiliary texts; they constitute a seemingly simple listing of the smallest perceptually distinct units of sound – phonemes – used in the Sanskrit language.
a i u Ṇ
ṛ ḷ K
e o Ṅ
ai au C
ha ya va ra Ṭ
la Ṇ
ña ma ṅa ṇa na M
jha bha Ñ
gha ḍha dha Ṣ
ja ba ga ḍa da Ś
kha pha cha ṭha tha ca ṭa ta V
ka pa Y
śa ṣa sa R
ha L
The upper-case italicized pure consonants at the end of each sūtra above are special markers, components of a meta-language. In this technical text, they are indicatory letters that show the end of each sūtra. They are known as IT (indicatory) markers or anubandha letters, literally “bound-after” letters. So, for instance, within the rules of the Aṣṭādhyāyī, Pāṇini uses the term “aC,” where the “C” is an anubandha letter. What this means for the user of the grammar is that she should start “gathering” phonemes, starting with “a” and ending with the anubandha “C.” This means that the user ends up with a set: “a i u Ṇ ṛ ḷ K e o Ṅ ai au C.” Now the user should discard all the anubandha letters, leaving only “a i u ṛ ḷ e o ai au.” These letters, of course, form the set of all the vowels used in the Sanskrit language.
In the Aṣṭādhyāyī, the term “aC” is thus a pratyāhāra, a “set denoter” that describes a series of letters by showing the first letter and the ending anubandha marker. So, the pratyāhāra “haL” is equivalent to the set of all the Sanskrit consonants; “jhaŚ” is the set of all voiced consonants, whereas “jhaṢ” is the set of all voiced aspirated consonants; “yaṆ” gathers all the semi-vowels; and so on. The pratyāhāras allow Panini to refer to the domains over which his specific rules operate without him having to repeat sequences of phonemes again and again.
An example may help clarify this usage. Rule 6.1.77 of the Aṣṭādhyāyī is “iko yaṇ aci,” which we may translate into “iK is replaced by yaṆ if aC follows.” We know already that “aC” is the set of all vowels, so we may further simplify this into “iK is replaced by yaṆ if a vowel follows.” Replacement of the remaining two pratyāhāras leaves us with “{ i k ṛ ḷ } is replaced by { ya va ra la } if a vowel follows.” A pratyāhāra gives us a partially ordered set, so we can finally conclude that what Pāṇini is telling us to do in rule 6.1.77 to the phonemes in the set “iK” – when a vowel follows – is:
Replace “i” with “ya”
Replace “k” with “va”
Replace “ṛ” with “ra”
Replace “ḷ” with “la”
Out of many, many pratyāhāras that could possibly emerge from the structure of the Śivasūtras, Pāṇini uses 43 in the Aṣtādhyāyī and refers to them in hundreds of his rules.[20] Alert readers may have noticed that “ha” appears twice in the sūtras, in the fifth one and the very last one, resulting in some possible ambiguity. The grammarians who came after Pāṇini of course noticed this as well and used the context of the usage within rules to resolve any ambiguities: “The understanding of a particular (application) is obtained by interpretation (in case of doubt); for, nondefinition (i.e., nonapplication of proper rules in the proper way) should not result from doubt.”[21] The “ha” in the very last sūtra is also necessary for some pratyāhāras such as “śaL,” which Pāṇini uses in certain rules.[22]
The construction of the Śivasūtras’ matrix of phonemes allows Pāṇini to achieve a remarkable degree of verbal economy within the Aṣtādhyāyī; the Śivasūtras themselves constitute a tiny miracle of meaningful succinctness and were apparently built with economy in mind. In a 1991 paper, the linguist Paul Kiparsky argued that “the structure of the Śivasūtras is entirely explicable on systematic grounds… [and] no other principles are needed than those used in the construction of the rest of Pāṇini’s grammar, namely the principle of economy and the logic of the special case and the general case (sāmānya/viśeṣa). If applied as rigorously in the construction of the metalanguage as in the formulation of the grammatical rules, they suffice to determine the structure of the Śivasūtras .”[23]
In 2005, Wiebke Petersen offered a mathematical proof (using formal concept lattices, planar graphs, and an enlarged S-alphabet) that the Śivasūtras are indeed optimally organized in three respects: “The length of the whole list is minimal”; the “length of the sublist of the anubandhas is minimal and the length of the whole list is as short as possible”; and the “length of the sublist of the sounds is minimal and the length of the whole list is as short as possible.”[24]
The extraordinary ingenuity of the Śivasūtras did not escape the ancients: legend has it that the god Śiva himself revealed the sūtras to Pāṇini, allowing Pāṇini to begin work on the Aṣṭādhyāyī.
*
The second auxiliary text attached to the Aṣṭādhyāyī is the Dhātupāṭha, a lexical list of 1,943 verb roots arranged into ten classes according to stem-formations which determine conjugation. The first verb root in the Dhātupaṭha, appropriately enough, is bhū, which is glossed as “To be, in the sense of existence.” Many of the verb roots will sound familiar to speakers of modern Indian languages: paṭh, to read; nṛt, to dance; likh, to write. And there is of course kṛ, to do, to make, from which we get the Sanskrit kartā, doer, and – famously – karman, action, work, deed.
The Gaṇapāṭha is an ordered listing of sets of nominal stems that can be used to form nouns, grouped according to grammatical function; these nominal bases include indeclinables, prefixes, pronouns, etc. An example of a nominal stem from the Gaṇapāṭha would be kram (“sequence, series, system, collocation”), from which we can form utkram (“to step up, ascend”), vyutkram (“to go apart”), padakrama (“a series of steps, pace, walking”), etc. The list of verb roots in the Dhātupāṭha is complete and final – no additions or emendations are allowed – but some of the lists of the Gaṇapāṭha are open-ended.[25] Later grammarians created a rich tradition of adding to these lists or creating alternate ones. The Gaṇapāṭha is therefore the most open part of Pāṇini’s system.
There are three more auxiliary texts, some of uncertain date and authorship. These are:
- The Uṇādisūtras, which describe the derivation of nominal stems through the use of Uṇādi affixes.[26]
- The Phiṭsūtra, which “deals with the accentuation of linguistic items that are not developed through a derivational process from underlying bases and affixes”; attributed to the grammarian Śantanu or Śāntanava, who may have predated Pāṇini.[27]
- The Lingānushāsana, which deals with “assigning gender to nominals based on their structure and meaning.[28]
*
We now have the raw materials of language – phonemes, verb roots, and nominal stems – but before we get to the heart of Pāṇini’s system, the rule-set which operates over these data, we should note an important aspect of the organization of the rules, which is again engendered by the overriding concern for economy. Consider the following sentences:
Give Caitra a cow.
A blanket to Maitra.
Also to Gopal.
Here, after the first sentence, each successive sentence “borrows” semantic sense from the sentence above it; they are therefore elliptical sentences. Pāṇini exploits this feature of natural language throughout his rule-set; almost every sūtra in the Aṣṭādhyāyī is an elliptical sentence which borrows meaning from the sūtra or sūtras above it.[29] Pāṇini will not repeat a word common to several successive sūtras; after using it once (this first mention is called adhikāra, “beginning”), he will omit the word thereafter.[30] The implicit presence of the word is known as anuvṛtti, recurrence.
In Pāṇini’s system, there is no limit put upon the number of sentences where anuvṛtti allows for the implicit presence of a word from a previous sentence. For example, the increment iṭ is first mentioned in rule 7.2.8; it then recurs implicitly in 70 successive rules, until rule 7.2.78.[31]
In the original text, rule 3.3.65 is typically terse: kvaṇaḥ vīṇāyāṃ ca. After restoration of all the words left out through anuvṛtti, the rule becomes “kvaṇaḥ vīṇāyāṃ ca pratyayaḥ paraḥ ca ādyudāttaḥ ca dhātoḥ kṛt kriyāyāṃ kriyārthāyām bhāve akartari ca kārake sañjñāyām ap upasarge vā nau (“The affix ‘ap’ comes optionally after the verb ‘kvaṇ’ (‘to jingle’) when ‘ni’ is in composition with it, as well as when it is without any upsarga or when ‘flute’ is meant”[32]). Sūtra 3.3.65 borrows words from 11 sūtras above it.
Amba Kulkarni, a Sanskritist and computer scientist, points out that the Aṣṭādhyāyī proper, the rule-set – in its entirety – comprises just 7007 words. If one undoes sandhi or word-joining throughout the rule-set, one ends up with 9843 words. But if you expand all the sūtras and restore all the words elided through anuvṛtti, the rule-set expands to 40,000 words. Paṇīni therefore achieves a 1/6 compression because of anuvṛtti. In terms of byte size, the compression is 1/3.[33]
*
The rules of the Aṣṭādhyāyī are of various types:
- saṃñjā, technical rules; “rules which assign a particular term to a given entity.”
- paribhāṣā, interpretive rules or metarules; “rules which regulate proper interpretation of a given rule or its application.”
- adhikāra, heading rules; “rules which introduce a domain of rules sharing a common topic, operation, input, physical arrangement, etc.”
- vidhi, operational rules; “rules which state a given operation [is] to be performed on a given input.”
- niyama, conditioning or restriction rules; “rules which restrict the scope of a given rule.”
- atideśa, extension rules; “rules which expand the scope of a given rule, usually by allowing the transfer of certain properties which were otherwise not available.”
- pratiṣedha, negation rules; “rules which counter an otherwise positive provision of a given rule.”
- vibhāṣā, optional rules; “rules which render the provisions of a given rule optional.”
- nipātana, ad hoc rules; “rules which provide forms to be treated as derived even though derivational details are missing.”[34]
The paribhāṣā or metarules aid in the interpretation of sūtras, while the adhikāra rules define the boundaries of domains. The vidhi sūtras or operational rules – aided by the conditioning rules and the extension rules – transform linguistic units and grammatical entities through affixation, augmentation, modification, and replacement (including deletion, because replacement by lopa or zero-element is possible). Some rules are universal while others are context sensitive; the sequence of rule application is clearly defined. Some specific rules can override other more general ones. Rama Nath Sharma writes, “Since Pāṇini formulated his rules based on his efforts to capture certain generalizations reflected in usage, he formulated some rules with a general (sāmānya) scope of application. These rules are termed general (utsarga). He also formulated other rules, relative to utsarga rules, and these commonly are termed specific (viśeşa). These rules define their scope within the scope of a general rule and often are treated as exceptions (apavāda) to that rule. Other types of specific rules in relation to a sāmānya are negations (pratiṣedha) and options (vibhāşā), etc. This clearly establishes a hierarchical relationship among rules. From the point of view of the various strategies employed in the application of rules, one may also find rule types such as nitya ‘obligatory’, para ‘subsequent’, antaraṅga ‘internally conditioned’ and bahirahga ‘externally conditioned’.”[35]
Rules can call other rules, recursively. The application of one rule to a linguistic form can cause the application of other rules, which may in turn trigger other rules, until no more rules are applicable.
The vidhi or operational rules that effect transformations are generally formulated as:
When “L E R” is observed, then E is replaced by X,
when L is the left context and appears directly before E (not all rules use this)
when R is the right context and appears directly after E (not all rules use this)
Let us say a Pāṇinian linguist wanted to use the verb root bhū (“To be, in the sense of existence”) to create a noun that denoted meaning “any state of mind or body, way of thinking or feeling, sentiment, opinion, disposition, intention.” The sequence of rule application would be:
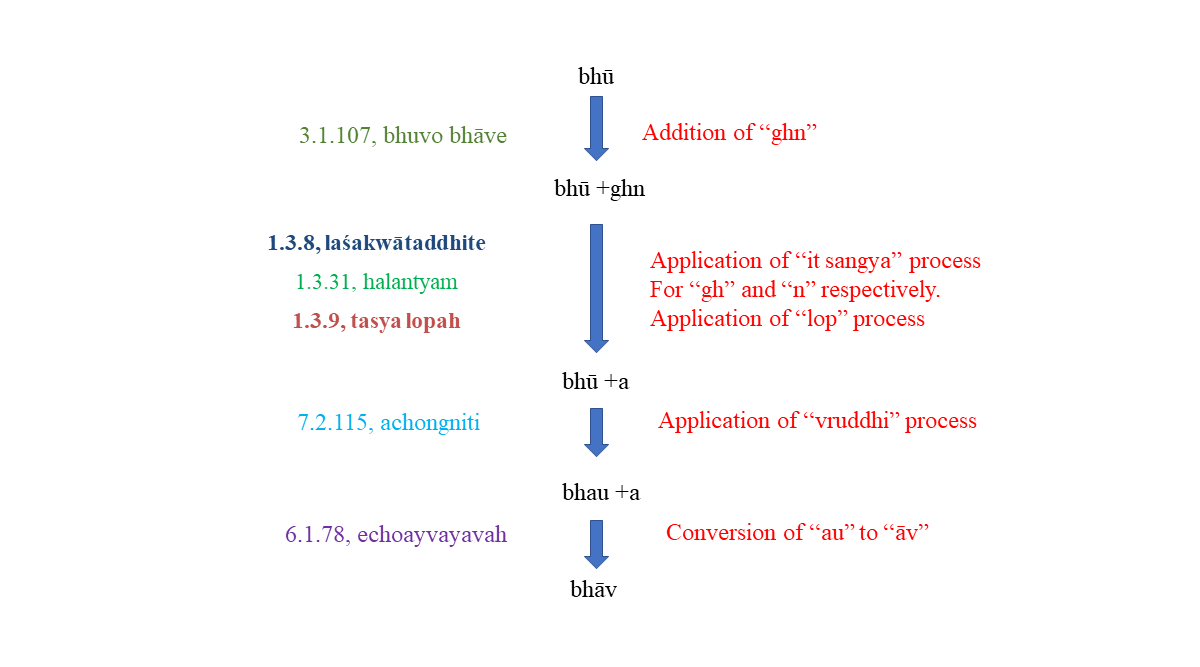
Each sequence of rule application takes an input and deterministically produces an output – modern programmers would immediately compare the workings of Pāṇini’s rules to those of string functions in modern programming languages. Note that our final output here – “bhāv” – is not yet a proper “word” according to the Pāṇinian system, where – as Saroja Bhate puts it – “none of the word-forms is derived in isolation i.e. without its connection with other items in a sentence. The inflectional derivation which is the final stage in each word takes place only after ascertaining the role of the word-form in a certain sentence.”[36] So once we have the context of what we want to say in a particular sentence or phrase, a further set of rules would be applied to produce a properly-inflected form of bhāv and the containing phrase, such as bhāvaṃ dṛḍhaṃ-kṛ, “to make a firm resolution”; or yādṛśena bhāvena, “with whatever disposition of mind.” Pāṇini’s system addresses word formation (primary and secondary derivation, compounding, the use of affixes and suffixes); nominal and verbal inflection; phonology; morphology; accent; and syntax.
Pāṇini’s derivation of sentences “is dependent upon the analysis of words by means of bases and affixes.”[37] That is, he uses word derivation as a means of deriving sentences; the strategy – as we see above – is to “derive words with reference to the conceptual structure (CS) of sentences. This procedure… enables him to derive sentences, even though he does not consider the sentence to be either the starting point or the terminal point of his derivational device.”[38] The grammatical categories which allow Pāṇini to do this are kārakas, which are syntactic-semantic categories which allow the assignment of roles to nominal expressions in relation to verbal roots. “A sentence is seen as a little drama played out by an Agent and a set of other actors, which may include Goal, Recipient, Instrument, Location, and Source.”[39] Once the central action of a phrase or sentence has been established, Pāṇini’s system inserts lexical items and assigns affixes to the various components according to the conceptual structure, finally producing a correctly inflected syntactic unit. Again, the central concern is for economy – word derivation as a means of producing sentences is simply the most efficient method possible within the Pāṇinian system.[40]
It should be clear by now that the Aṣṭādhyāyī is an “automaton that generates Sanskrit words and sentences.”[41] It is, in fact, a complex algorithm that can generate an infinite number of grammatically correct Sanskrit sentences using a finite set of formal rules. The entirety of Pāṇini’s rule-set can be printed in about forty pages of 12-point text.
*
The publication of the Aṣṭādhyāyī was an epochal event within the already-rich tradition of Indian linguistics. Pāṇini’s work deals with both the language of his time, and also the already archaic usages of the Vedic hymns, already a thousand years or more removed. But it is only after the Aṣṭadhyāyi that the contemporary language that Pāṇini described became known as “Sanskrit,” which is actually a descriptor – saṃskṛta is the neuter form of saṃskṛtam, from sam, “together,” and kṛ, “to do, make,” and therefore the language has been “put together, well-formed, highly wrought, perfected.” The Aṣṭādhyāyi marks the beginning of what is sometimes called “Classical Sanskrit” – in contrast with “Vedic Sanskrit” – and the Sanskrit that lives on today.
Sanskrit therefore becomes – uniquely – a natural language that shares some of the features of a formal language, a language “with explicit and precise rules for its syntax and semantics,” as the Oxford Dictionary of Computing puts it. Formal languages “contrast with natural languages such as English whose rules, evolving as they do with use, fall short of being either a complete or a precise definition of the syntax, much less the semantics, of the language.”[42] As Shrinivasa Varakhedi puts it, Sanskrit is a “natural but restricted” language, with a formal description that captures its syntax completely.[43]
This aspect of Sanskrit has some interesting results. Gerald Penn and Paul Kiparsky argue that “The underlying formalism to Pāṇinian grammar, while our knowledge of it is incomplete, presents enough evidence to conclusively demonstrate that it is far greater in its expressive power than either RL [Regular Languages] or CFL [Context-Free Languages]. Pāṇini has nevertheless anticipated modern generative syntactic practice in defining for himself a very versatile tool which he then applies very thriftily to advance his own objectives of grammatical brevity and elegance… [The] greatest difference between Pāṇini’s own formalism and the standard string-rewriting systems concomitant with Chomsky’s hierarchy… is its built-in capacity for disambiguation. Pāṇini’s grammar, through its use of rule precedence and other meta-conventions, generates a single derivation for every grammatical sentence of Sanskrit. Not even a single one of the standard Chomskyan systems possesses this property, and it is this lack of theirs, rather than some inherent quality of the syntax of human languages that is responsible for the now-widespread use of numerical reasoning and statistical pattern recognition methods in natural language processing. These are required in order to curb the natural propensity of these algebras to overgenerate. Through the lens of contemporary NLP [Natural Language Processing], the most amazing fact about the Aṣṭādhyāyī is not that it produces so many correct derivations, after all, but that it simultaneously avoids so many incorrect ones.”[44]
The use of word-joining, sandhi and its associated sound changes across word boundaries, does make it possible to introduce syntactic ambiguity. For instance, the sentence “vṛkṣa iha tiṣṭhati” can be parsed as “vṛkṣaḥ / iha / tiṣṭathi” (“The tree stands here”) or “vṛkṣe / iha / tiṣṭhati” (“He stands here in the tree”).
And yet, even in these situations, Pāṇini’s system will produce accurate derivations for this grammatically correct sentence. According to Paul Kiparsky, “‘Sentence’ here includes meaning and pronunciation. So there is a distinct derivation for each reading of an ambiguous sentence (in so far as the rules of the grammar distinguish it) and of course each sandhi form will arise by different applications of sandhi rules.”[45]
Pāṇini’s formal definition of Sanskrit syntax and the (relatively) easy parsing of sentences induces some people – especially Indians in nativist or full-on nationalist mode – to claim that Sanskrit would be a perfect language for computer programming.[46] This claim demonstrates an essential misunderstanding of what programming languages need to do: they need to be machine-parsable, and they need to give unambiguous instructions to computing machines.
But producing a parsing-friendly subset of English or any other natural language has not really been a problem in computing for a half-century or more. And also, the claim demonstrates an ignorance of how syntax relates to semantics, to meaning. Despite its syntactic precision, Sanskrit – in its “natural” spoken and written forms – produces as much semantic ambiguity as any other language. And this is not just because of its huge number of synonyms and homonyms, or the possibilities of ambiguity introduced by features like sandhi (which have been exploited by poets for some truly astonishing poetry); Sanskrit is semantically ambiguous because meaning is context-dependent, and linguists and philosophers in India have always been aware of this. Their favourite example to demonstrate this aspect of all language has been the syntactically simple sentence, “The sun has set.” The aesthetic philosopher and rhetorician Mammaṭa wrote in the 11th century CE:
The denoted meaning of a word is one and the same for all persons bearing it; so that it is fixed and uniform; the denoted or directly expressed meaning of the words ‘the sun has set’ never varies (is fixed), while its suggested meaning varies with the variation in such accessory conditions as the context, the character of the speaker, the character of the person spoken to, and so forth. For instance, the words “the sun has set” suggests (1) the idea that “now is the opportunity to attack the enemy” (when they are addressed by the general to the king);—(2) “that you should set forth to meet your lover” (when addressed by the confidant to the girl in love)…
Mammaṭa continues until ‘(10)—“my love has not come even today” (when spoken by an impatient girl waiting for her beloved’s return from a journey); thus, in fact, there is no end to the number of suggested meanings.”[47]
The linguists, writers, poets and aesthetic philosophers of India have always been aware that this ambiguity produced by language, the endless multiplicities of meaning produced by a seemingly simple utterance, is a feature of language, not a bug. The most prominent Indian theorization of poetic beauty in language is built around the concept of dhvani, reverberation, resonance; according to this theory, the best poets purposefully produce directed ambiguity, an endless upwelling of meaning and associations that is sometimes compared to the echoing of a bell.[48]
People working in domains other than literature have been annoyed enough by this inborn ambiguity of language to try and produce Sanskrit-based solutions. The meta-language deployed by Pāṇini in the Aṣṭadhyāyī is one such example of an artificial language created in the pursuit of precision and non-ambiguity. Śāstric or scientific Sanskrit has been used in various disciplines, particularly Nyāya or logic, to make non-ambiguous statements. The philosophers of the Navya-Nyāya (“New Logic”) school, beginning in the 11th century CE, developed one such paribhāṣā or restricted language. In this technical language, the natural-Sanskrit sentence Rāmaḥ hastena brāhmaṇāya dhanam dadāti (“Rama gives money to a Brahmin with (his) hands”) becomes rāma-niṣṭha-kartṛtva-nirūpaka-hasta-niṣṭha-karaṇatva-nirūpakabrāhmaṇa-niṣṭha-sampra-dānatva-nirūpaka-dhana-niṣṭha-karmatva-nirūpakadānakriyā, or “An activity of giving characterized by the agent-hood in Rama, the instrument-ness in the hand, the recipient-ness in a Brahmin, and the object-hood in money.”[49]
Contemporary programmers many notice a certain familial resemblance to RDF and OWL, modern computing dialects designed for computer-parsable semantics. Amba Kulkarni points out that technical language of Navya-Nyāya takes advantage of native features of Sanskrit: “Sanskrit is very rich in compound formation. This feature of Sanskrit has been utilized to its full extent by the Indian logicians in describing cognitive structures using the technical language of NN [Navya-Nyāya]. Such expressions are typically exceptionally long, many-a-times one compound running into pages.”[50] Further, “the technical language of Navya Nyāya is built on top of the classical Sanskrit. In this language, technical words of Navya-Nyāya are intermixed with the original words in such a way that the resulting expression is unambiguous. Thus, a Navya-Nyāya expression has the complete power of expressibility of a Natural language at its disposal. And probably, it is because of this reason that we find use of technical language of NN [Navya-Nyāya] in various fields of Humanities such as Vyākaraṇa ‘grammar,’ Sāhitya ‘literature,’ Mīmāṃsā ‘exegesis,’ etc.”[51] Indeed, one of the “new grammarians” we will meet shortly in this essay, Bhaṭṭoji Dikṣita, used this technical language in a grammar which is still used widely today.
A restricted śastric Sanskrit could, then, be applied profitably to computing; such a Sanskrit would perhaps provide semantic precision along with natural-language-like legibility and suppleness. I’d be particularly intrigued by the use of long Sanskrit compounds in relation to functional programming – I’ll admit to fantasizing sometimes about a complete application written as one very long Sanskrit word. Or, indeed, as a single, seemingly small Sanskrit syllable, as in Oṃ. The practical exigencies – economic and linguistic – of the world we live in today is probably going to keep this vision firmly in the realm of fantasy.
And yet, it is possible to argue that someone has already programmed in Sanskrit, or at least in a restricted technical Sanskrit. During the inaugural speech at the First International Sanskrit Computational Linguistics Symposium in 2007, Gérard Huet (computer scientist, linguist, mathematician) stated, “Not only Pāṇini was by far the first linguist in recorded history, but I claim he was the first informaticien, 24 centuries before computers came into existence.”[52]
In a pair of recently-published papers, John Kadvany shows how and why this is true.[53] Most of us have been conditioned by modern media to think of computation as a mechanical process that is somehow accomplished with silicon-based chips and electricity in physical incarnations of Turing’s machines. People who have been formally trained in computer science will of course know of the lambda calculus, introduced by Alonso Church in the nineteen thirties; the lambda calculus is a formal system in mathematical logic based on function abstraction and application. It is also a universal model of computation that can accomplish anything a Turing Machine can.
The least-known model of general computation – at least to the lay person – is the one produced by the production/rewrite systems developed by Emil Post through the nineteen twenties and thirties but published in 1943. Post’s system is equivalent in power to a Turing Machine, but is based solely on recursive string-rewriting. Which is – of course – exactly what Pāṇini does with his meta-language in the Aṣṭādhyāyī. Kadvany writes, “Pāṇini’s natural language methods are sufficient to define computational processes generally. For Pāṇini has mastered a single algorithmic technique which is sufficient for such generic representation. The size and complexity of Pāṇini’s system makes that accomplishment hard to recognize, but it provides a direct link to contemporary computation and formalization. In modern terms, Pāṇini’s replacement rules are instances of formalisms studied by Emil Post in the 1930s and 1940s.”[54] And further, “The first computing language – again, for our purposes, a generic formalism, described through a metalanguage for representing exact generative symbolic procedures of any kind – was devised… by the Indian grammarian and linguist Pāṇini. The formalism is not identical with Pāṇini’s Sanskrit grammar, but is a significant part of it, constituting the grammar’s formidable derivational method… Pāṇini’s basic method was rediscovered, we can now say, in the 1920s and 1930s by Emil Post through his production/rewrite systems…”[55]
To be clear: Pāṇini and his intellectual successors did not use his meta-language to compute anything but the Sanskrit language. But the fact remains that with his “generative calculus” – which, as S. D. Joshi observed, is “actually the main thrust of the Aṣṭādhyāyī – Pāṇini created the world’s “first formal system, well before Gottlob Frege’s late nineteenth century Begriffsschrift for first-order predicate logic.”[56] And he used it to code a language, Sanskrit.
*
Given the complexity, subtlety, and terseness of Pāṇini’s engine, it isn’t surprising that there are areas of ambiguity within the Aṣṭādhyāyi (bugs!) and consequent controversy around his heavily technical sūtras, which are often couched in an algebraic meta-language which would be completely unintelligible even to a highly sophisticated Sanskrit speaker of his time who lacked specialized training. Commentaries soon began to be written about the Aṣṭādhyāyi, as they often were about texts in the sūtra form. A sūtra is always a short technical sentence. The first and most basic form of commentary on a sūtra is a vṛtti, a “paraphrase statement” – sometimes written by the author of the sūtra – which facilitates proper understanding. Sūtras and vṛttis are then sometimes subjected to vārttikas, critical appraisals of a focus sūtra or paraphrase; in the case of the Aṣṭādhyāyi, a vārttika would examine “a sūtra from the express point of view of what is stated (ukta) by a rule, what is not stated (anukta) by a rule, and what has been poorly stated (durukta)… A vārttika, by way of accepting a sūtra as its focus, puts a sūtra to test.”[57]
The first major vārttika commentary on the Aṣṭādhāyi was produced by Kātyāyana (circa 300 BCE). In his work, Kātyāyana examined each of his selected Pāṇinian sūtras “in terms of its intended meaning and application in view of under application, over application, or very rarely, no application at all.”[58]
Kātyāyana’s critical remarks and suggestions elicited an intervention from the great linguist Patañjali (mid-2nd century BCE) in the form of a bhāṣya, a detailed exposition of an earlier text which includes citations and testing of assertions which would lead to acceptance or rejection, along with step-by-step reasoning. “The discourse style of [Patañjali’s commentary] accepts [Kātyāyana’s] vārttikas as pratīka ‘focus (symbol)’ and offers its deliberations (vyākhyāna) by first introducing a topic and then discussing the same in view of questions (praśna), answers (uttara), refutations (ākṣepa) and resolutions (samādhāna), all illustrated with examples (udāharaṇa) and counter-examples (pratyudāharaṇa). The bhāṣya thus takes the vārttika as its pratika ‘focus’ and presents its discussion of a sūtra in view of examples and counter-examples. A bhāṣya thus, by way of accepting a vārttika as its focus, again puts a sūtra to test. This interlocking dependency of focus on sūtra, vṛtti and bhāṣya also became the main style of representation of knowledge in many other branches of learning in ancient India.”[59]
(An aside: the Indian commentarial tradition is even more complex and variegated than the above quotation suggests; an author working in the 16th century CE lists 12 distinct forms of commentary in his typology.[60] Important sūtra texts had dozens or even hundreds of commentaries written about them, some of them important intellectual landmarks in themselves. As we’ll see shortly, through his response to Kātyāyana’s work, Patañjali wrote a landmark text on the Aṣṭādhyāyī; but Kaiyaṭa’s Mahābhāṣya-Pradīpa (“Light on the Mahābhāṣya,” 11th century CE), a commentary on Patañjali’s commentary, is also considered essential scholarly reading, without which a full understanding of Patañjali’s work is impossible.[61] Knowledge production as a web of interrelated voices speaking to each other over centuries is a given here. Reading a prominent text written in the sūtra form without engaging with its commentaries will, at best, allow only a very partial understanding of the issues brought up by the text.)
Patañjali addresses many of the issues brought up by Kātyāyana in his vārttikas, and in many cases rejects Kātyāyana’s conclusions or solutions. “Many of those vārttikas forced the author of the bhāṣya [Patañjali] to arrive at some satisfactory resolution to problems raised by them. It is in these contexts that Patañjali offers some brilliant resolutions.”[62] The tradition regards Patañjali’s insight into Pāṇini and Kātyāyana, and his own innovations with such reverence that his text became known simply as Mahābhāṣya, “The Great Commentary.” Patañjali’s work is widely accepted as “the first ever serious attempt to present a successful theory of linguistics, especially grammar.”[63]
Pāṇini, Kātyāyana, and Patañjali are regarded as the three sages, munitrayī or trimuni, of the classical Indian linguistic sciences. According to the principle of yathottaraṃ munīnāṃ prāmāṇyam, each succeeding sage is accorded more authority, allowing for a self-correcting tradition which regards Patañjali as the high point of the early Pāṇinian tradition. The three sages constitute the beginning of a vast stream of argument, research, analysis, and commentary that continues into modernity.
*
The Aṣṭādhyāyi is not a pedagogical grammar designed for the teaching of Sanskrit; it is an engineered device that describes and generates a language. Its architecture reflects the intention of its maker: the first five chapters of the text are devoted to analysis, to decomposition of language into small and smaller units; the rules of chapters six through eight then synthesize words and sentences out of these units.[64] But beyond this overall binary division, the division of the rules into chapters does not result in a division according to topic. The overriding concern for economy, and for the deployment of inheritance-ready headings and anuvṛtti, recurrence, leads to the scattering of rules that may relate to a common subject across the chapters.[65] The chapters are operational units, not divisions intended to aid comprehension; rule-placement is determined by efficiency and engineering coherence.
The result is an elegantly-built device that is hard to understand (object-oriented programmers may be familiar with similar problems). Traditionalists insisted that the Aṣṭādhyāyī was really a “tiger-faced cow,” a vyāghramukhī gauḥ, that once a young student got past the initial terror of facing Pāṇini’s frighteningly incomprehensible sūtras, swift and complete understanding would follow. Nevertheless, in the 11th century CE, a scholar named Dharmakīrti produced a text called the Rūpāvatāraḥ (“Descent of Forms”), which rearranged Pāṇini’s sūtras in functional blocks most conducive to grammatical pedagogy.[66] Dharmakīrti began a tradition of prakriyā or “derivation” texts, which do not follow the Aṣṭādhyāyī’s sequence of sūtras but rearrange them thematically around various grammatical topics. The prakriyā text par excellence is the Vaiyākaraṇa Siddhānta Kaumudī (“The Illuminator of Grammatical Principles”), written by Bhaṭṭoji Dīkṣita during the 17th century CE. Rama Nath Sharma describes the Siddhānta Kaumudī as “a theoretical marvel… [a] marvel that rooted out all competition and brought the Pāṇinian tradition to a full circle… His treatment of the sūtras is very brief, but very insightful, precise and thorough and comprehensive… Bhaṭṭoji Dikṣita's brilliant explanations of the grammatical tradition of the trimuni ‘three sages’ established him as the muni ‘sage’ of the new school of grammar (navya-vyākaraṇa)… The Vaiyākaraṇa-sidhānta-kaumudī represents the pinnacle of excellence of grammatical knowledge.”[67]
The Vaiyākaraṇa Siddhānta Kaumudī did indeed become the primary text for teaching grammar, and is still widely used in Indian universities wherever Pāṇinian grammar is taught. There was, perhaps inevitably, a backlash from traditionalists who argued that the rearrangments and simplifications of the prakriyā texts prevented students from truly understanding the Aṣṭādhyāyī and comprehending the context for each of Pāṇini’s sūtras, which would only be possible when the student confronted Pāṇini’s original sequences. The argument between the traditionalists and the innovators rose to a high pitch in the early 19th century CE and continues into the present.
*
Europeans discovered Pāṇini’s work during the great flowering of Orientalist learning during the 18th century CE, and first through the efforts of British civil servants. As the British trading presence converted itself into an occupying empire – the “British Raj” – a group of European scholar-bureaucrats found it necessary to acquire a knowledge of Sanskrit (hitherto ignored by the traders) during the effort to set up an Indo-British judiciary system that would graft European procedures over existing Indian mores and laws. In January 1784, Sir William Jones, a polymathic judge founded the Asiatick Society at Fort William in Calcutta. In the Third Anniversary Discourse of the Society in 1786, Jones made his famous pronouncement:
The Sanscrit language, whatever be its antiquity, is of a wonderful structure; more perfect than the Greek, more copious than the Latin, and more exquisitely refined than either, yet bearing to both of them a stronger affinity, both in the roots of verbs and in the forms of grammar, than could possibly have been produced by accident; so strong indeed, than no philologer could examine them all three, without believing them to have sprung from some common source, which, perhaps, no longer exists: there is a similar reason, though not quite so forcible, for supposing that both the Gothick and the Celtick, though blended with a very different idiom, had the same origin with the Sanscrit; and the old Persian might be added to the same family, if this were the place for discussing any question concerning the antiquities of Persia.[68]
This relationship of European languages and Sanskrit through a common source – eventually known as Proto-Indo-European – made the learning of Sanskrit a sine qua non for philologists and linguists in the 19th century CE. Max Müller, the German-born Indologist, put it bluntly: “a comparative philologist without a knowledge of Sanskrit is like an astronomer without a knowledge of mathematics.”[69]
“Asiatick Jones” had encountered the Aṣṭādhyāyī during his studies with Indian pandits, but he declared it “dark as the darkest oracle,” and quoted a Sanskrit couplet which declared that the grammar “destroys the pride of all the learned in this world: from this, the best scholars, the most intelligent men, become full of doubt, and frequently err from chapter to chapter.”[70]
Nevertheless, despite the density of the source material and cultural gaps, scholars persisted, especially the Germans, led by Franz Bopp. In 1839-40, Otto Böhtlingk – a Russian philologist of German origin – published Pânini’s acht Bücher grammatischer Regeln, a two-volume translation of the Aṣṭadhyāyī. Forty-seven years later, he published a second edition, Pânini’s Grammatik, which contained not only the text and a German translation, but also “indices, word and root lists, grammatical commentaries, and other useful supplements,” which comprised almost half the book.[71] Leonard Bloomfield – the “father of structural linguistics” – described what happened over these decades as follows:
Around the beginning of the nineteenth century the Sanskrit grammar of the ancient Hindus became known to European scholars. Hindu grammar described the Sanskrit language completely and in scientific terms, without prepossessions or philosophical intrusions. It was from this model that Western scholars learned, in the course of a few decades, to describe a language in terms of its own structure.[72]
Bloomfield himself studied Sanskrit as a graduate student at the University of Wisconsin and later in Germany. As an assistant professor at the University of Illinois, he taught elementary Sanskrit even as he began his own research, “using the Pāṇinian method… and studying Pāṇini.”[73] Bloomfield was effusive in his praise of the Aṣṭādhyāyī: it was “a linguistic achievement beyond any it [i.e. European scholarship] had known”; it was “one of the greatest monuments of human intelligence” and “an indispensable model for the description of language.”[74]
Given Bloomfield’s close study of Pāṇini, it is inevitable that he deployed these techniques in his own work. As Paul Kiparsky observes:
Western grammatical theory has been influenced by [Pāṇini’s work] at every stage of its development for the last two centuries. The early nineteenth-century comparativists learned from it the principles of morphological analysis. Bloomfield modelled both his classic Algonquian grammars and the logical-positivist axiomatization of his Postulates on it.[75]
In 1927, Bloomfield published “On Some Rules of Pāṇini,” a detailed technical analysis of some of the statements in the Aṣṭādhyāyi concerning pronouns. In the paper, he refers to various “traditional Pāṇinian grammatical works, including Patanjali’s Mahabhāsya, Kaiyaṭa’s Pradipa, Nāgeśa’s Uddyota, the Kāsikā, Bhattojidīksita’s Siddhāntakaumudī, Nāgeśa’s Paribhāṣenduśekhara, and Böhtlingk’s Pânini’s Grammatik.”[76] In his paper, “The Influence of Pāṇini on Leonard Bloomfield,” David E. Rogers offers a detailed and persuasive analysis of the influence of the Aṣṭādhyāyī on Bloomfield’s Language (1933), which “is considered the initial work in the establishment of the American structuralist paradigm.”[77] Rogers’ paper is summarized thus: “Leonard Bloomfield’s synchronic grammatical works were heavily influenced by the sixth century B.C. Indian grammarian Pāṇini. Word formation, compounds, suppletion, zero, form-classes, and generality and specificity in Bloomfield’s Language, Eastern Ojibwa, and The Menomini Language are correlated with their counterparts in Pāṇini’s grammar of Sanskrit. Selections from a manuscript of Bloomfield’s translation and annotation of the Kāśikā, a traditional Sanskrit work on Pāṇini’s grammar, provide concrete evidence for the influence of Pāṇini on Bloomfield.”[78]
So, as Paul Kiparsky tells us:
Theoretical linguists of all persuasions are in addition impressed by [the Aṣṭādhyāyī’s] remarkable conciseness, and by the rigorous consistency with which it deploys its semi-formalized metalanguage, a grammatically and lexically regimented form of Sanskrit. Empiricists like Bloomfield also admired it for another, more specific reason, namely that it is based on nothing but very general principles such as simplicity, without prior commitments to any scheme of “universal grammar”, or so it seems, and proceeds from a strictly synchronic perspective. Generative linguists for their part have marveled especially at its ingenious technical devices, and at intricate system of conventions governing rule application and rule interaction that it presupposes, which seem to uncannily anticipate ideas of modern linguistic theory (if only because many of them were originally borrowed from Pāṇini in the first place).
*
The influence of Pāṇini and pre-modern Indian linguistic science on modern linguistics is profound and widespread. Ferdinand de Saussure was “an impeccably qualified Sanskritist” who received his 1880 doctoral degree for a thesis titled De l’emploi du genitif absolu en Sanscrit; he taught Sanskrit and Indo-European languages in Paris and Geneva for nearly three decades and devoted some of his time to obsessively searching for hidden messages in Vedic hymns (anagrams and “hypograms”).[79] Many of Saussure’s innovations seem heavily reminiscent of ideas developed by the grammarian and linguistic philosopher Bhartṛhari (circa 5th century CE). Lingue and parole, for instance, are intriguingly similar to Bhartṛhari’s prātikadhvani and vaikritadhvani, and the notion of the linguistic “sign” echoes Bhartṛhari’s explication of the sphoṭa theory, which tries to account for the production of unified semantic meaning from discrete linguistic units.[80]
Writing in 1953, the comparative linguist W. S. Allen observed that “the link between the ancient Indian and the modern Western schools of linguistics is considerably closer in phonetics than in grammar. For whilst Pāṇinean techniques are only just beginning to banish the incubus of Latin grammar, our phonetic categories and terminology owe more than is perhaps generally realized to the influence of the Sanskrit phoneticians.”[81] He goes on to quote J. R. Firth: “Without the Indian grammarians and phoneticians whom [William Jones] introduced and recommended to us, it is difficult to imagine our nineteenth century school of phonetics.”[82] Writing with Maurice Hall, Roman Jakobson traces the history of the “phoneme” as follows: “The search for the ultimate discrete differential constituents of language can be traced back to the sphoṭa-doctrine of the Sanskrit grammarians and to Plato’s conception of στοιχεῖον [Greek “stoicheion,” an alphabet] but the actual linguistic study of these invariants started only in the 1870’s…”[83]
The influence of the Sanskrit grammarians and linguists was particularly heavy in the United States, resulting in – as E. B. Emeneau put it – an “American” school of linguistics that is particularly Bloomfieldian and Pāṇinian in its distinguishing features.[84] Some readers may at this point be wondering, “What of Noam Chomsky, the ‘father of modern linguistics’ and pioneer of generative grammars? Did he know anything about Pāṇini’s prior work? Or Bloomfield’s, for that matter?”
I was curious about this myself, and was surprised to find that in recent interviews Chomsky has asserted that “when working out his ideas on rule ordering for his Master’s thesis on Morphophonemics of Modern Hebrew in 1951, he did not have access to Bloomfield’s ‘Menomini Morphophonemics’ 1939 paper [published in Travaux du Cercle Linguistique de Prague, in Czechoslovakia], suggesting that the generative model of linguistic analysis he developed at the time was more or less original with him.”[85]
Bloomfield had, in this “Menomini Morphophonemics” paper, used rule-ordering in a very Pāṇinean mode to describe the phonological variations of the morphemes in the language of the Native American Menomini people. The Pāṇinean influence is apparent from the very beginning of the paper: beginning with the second paragraph, Bloomfield uses the word sandhi several times (“The words in a phrase and the members in a compound word differ but little in different combinations; such variations as occur, constitute the external or syntactic sandhi of the language…,” “ Simple words and the members of compounds… resolve themselves… into morphologic elements which vary greatly in different combinations; the present paper describes these variations, the internal sandhi or morphophonemics of the language”).[86] A prior knowledge of Bloomfield’s work would mean that Chomsky was standing on the shoulders of giants, rather than inventing something completely new with his 1951 thesis.
Chomsky wrote this thesis in a department which – by his own account – was full of “Bloomfield’s students and close friends”; his mentor, teacher and supervisor, Zellig Harris, was an ardent admirer of Bloomfield’s work.[87] Chomsky’s rather over-elaborate explanation for his assertion that none of these people told him about “Menomini Morphophonemics” is that in the post-war fifties, American scholars were so steeped in contempt for Europe that nobody paid any attention to anything published in Europe.[88]
In 1999, John G. Fought published a paper that examined – in part – “Bloomfield's morphophonemic approach to phonology and its contribution to Chomsky’s early generative phonology”; in regard to Chomsky, he writes, “I don’t believe Chomsky’s claim that he didn’t know about Bloomfield’s paper at the time in question. Indeed, I believe that he not only knew about the paper but was quite familiar with the key elements of it during at least a part of this period. For one thing, he must have been exposed to it by Zellig S. Harris, who was then still his mentor, at least in Harris’ book Methods in Structural Linguistics and very probably in one or more of his classes as well… [In chapter 14 of Harris’s book] Bloomfield (1939) is discussed twice.”[89]
Fought concludes “I believe that the similarities between the strategy and techniques of Bloomfield’s Menomini Morphophonemics and the architecture of early Chomskyan generative phonology are most plausibly explained by Chomsky's prior acquaintance with the Bloomfield paper, either directly or through summaries in [Zellig] Harris (1951). I regard Chomsky’s denial of any such influence by Bloomfield as another example of his solipsism, though perhaps a less glaring one than his failure even to mention Harris in this connection.”[90]
In his 2003 book, Toward a History of American Linguistics, E. F. K. Koerner devotes a chapter to “the origins of morphophonemics in American linguistics.” Julie Tetel Andresen writes in a review of Koerner’s book:
The story crucially involves Chomsky’s supervisor Zellig Harris, whose Methods in structural linguistics (1951), which had been circulating in manuscript form since 1946, contains a section entitled ‘Morphophonemics’. That Chomsky knew of Harris’s Methods before 1951 is clear, since K notes at the outset that Harris thanks Chomsky in his preface for helping with the proofs (210). K’s story may start there (case closed: even if Chomsky never read Bloomfield’s paper, he would have absorbed the essentials of Bloomfield’s ideas about rule ordering through Harris’s work), but it does not end there. K’s main goal… is to unravel what he calls the counter-history that has been woven over the decades about Chomsky’s supposed originality with respect to rule ordering, and which includes Chomsky’s repeated assertions about his ignorance of Bloomfield’s article... K identifies the 9th International Congress of Linguistics held in Cambridge, MA, in August 1962 as the decisive event, ‘ably prepared and effectively run’ by Morris Halle, where the strategy had become ‘to sell Chomsky’s ideas as having little to do with the linguistics of his American teachers and predecessors … [such that] … connections with the work of Chomsky’s immediate predecessors had to be minimized, if not erased’ (234). It was after this event that the story of the noncumulative, that is, so-called revolutionary, nature of generative linguistics took shape and took hold and has now been reproduced in textbooks and historical accounts to such an extent that ‘this concoction has become accepted as historical fact by many followers’ (235). The way K sees it, by contrast, American linguistics during the 1940s and 1950s involved more evolution than revolution. His point, however, is not to chastize Chomsky—or anyone else—for distorting the historical record. In fact, he goes so far as to say that ‘it appears to me that Chomsky is at least doing what most of us do, and more often than not unconsciously, namely to reinterpret our own past as we grow older, while at the same time our memory of this past has become much less reliable than we may believe it to be’ (244). This is the point of K’s historiography: to let the record speak for itself rather than any one individual (or group of individuals) at any particular stage in a career or a theoretical moment, so that the reader may draw his own conclusions. One of the conclusions I draw from this episode is that Chomsky, in disavowing influences from immediate predecessors, is making a bid for originality that supports the further formalist tenet that utterances (and, by extension, entire theories) are unconditioned, in the behaviorist sense of the term, by immediate circumstance.[91]
According to Chomsky, his 1951 thesis was treated with an “almost total lack of interest” in his department. The only person who paid attention to it was Henry M. Hoenigswald, a linguist and seasoned Indo-Europeanist “who read the work carefully and made helpful comments.”[92] Hoenigswald was “steeped in Panini”; it’s hard to believe that someone like him would see a young man trying to create a generative morphophonemics and not mention prior work, at least that done by Bloomfield.[93]
These bids for originality may be observed as larger civilizational scales as well. I like to think that as I’ve gotten older, I’ve become somewhat inured to colonial and post-colonial erasures of history and culture. But it still rankles when I chance upon a blog post titled “Parsing: a timeline,” and read the blithe, unsupported assertion, “By 2018, Pannini [sic] will be the object of serious study. But in the 1940’s and 1950’s Pannini will be almost unknown in the West. This means that Pannini will have no direct effect on the other events in this timeline [of parsing].”[94] One might recall Paul Kiparsky’s assertion that “Western grammatical theory has been influenced by [Pāṇini’s work] at every stage of its development for the last two centuries,” and wonder how steeped-in-Pāṇini scholars like Hoenigswald and Bloomfield might react to this very curious statement.
*

In 2004, the Indian Department of Post released a 5-rupee stamp commemorating the achievements of Pāṇini. In the image, Pāṇini sits facing east – an auspicious direction – and writes in Brahmi script. It’s not at all certain that Pāṇini used epigraphic methods extensively to work on his system, so this is a curious artistic choice. Certainly the enormous emphasis on economy on the Aṣṭādhyāyī would lead us to believe that Pāṇini lived in a world where the transmission of learning was mainly through oral methods. At the very least, the scale of Pāṇini’s achievement should make us reconsider how easily we associate orality with illiteracy; he came from a culture which knew of writing (recall the verb root likh in the Dhātupāṭha), but which valued spoken and chanted language above all else – and yet this was a fiercely literate and intellectually sophisticated ecumene. Long after Pāṇini and the spread of writing as a tool, Indic culture has held on to the valorisation of the oral; sound itself was sacred in the beginning, and it remains so.
The influence of Pāṇini on knowledge production in India has been enormous, especially in the ṣāstras or sciences. A sūtra is literally a “thread,” but there is also a very well-known formulation of what makes a good sūtra: alpākṣaram asandigdham sāravat viśvatomukham / astobham anavadyaṃ ca sūtram sūtravido viduḥ (“A sūtra should have the least number of syllables, should contain no doubtful words, no redundancy of words, should have unrestricted validity, should contain no meaningless words and should be faultless!”).[95] Pāṇini’s sūtras are the shining exemplars of this form; Patañjali insisted that in Pāṇini’s work “it is not possible, even for a single sound segment, to be anarthaka ‘non-meaningful.’”[96] All scientific and logical works aspired to the condition of the Aṣṭādhyāyī. Nowhere is this more apparent than in the discipline of grammar, leading to the wry observation, ardhamatrālāghavena putrotsavam manyante vaiyākaranáh (“For grammarians, the saving of even half a mora in a sūtra is cause for as much celebration as the birth of a son”).[97]
An even more profound effect than the desire for economy has been the method of Pāṇini’s system: decomposition followed by synthesis. According to the grammarian Bhartṛhari (5th century CE), Tad dvāram apavargasya vaṅmalānam cikitsitam / Pavitram sarvavidyānām adhividyam prakāśate (“This [grammar] is the door of liberation, an antidote against the faults of speech; it purifies every kind of knowledge, it shines forth in [every kind of] knowledge”).[98] That grammar is the door of liberation might seem like a bizarre assertion (perhaps especially to high school teachers) until one thinks about the Sanskrit word for grammar, vyākaraṇa – literally, vyākaraṇa is just “analysis” in the sense of separation, distinction, taking apart. So, once you’ve decomposed a system – such as a given language – into its very smallest units, you can then observe the interactions of these components and learn how they interact, how they fit together. And then you can use the system, predict its behaviour, and perhaps hope even to transcend it. Vyākaraṇa is therefore the “science of sciences:” grammar teaches you how to think. Grammar as a discipline and as a way of understanding the world is significant enough on its own that a 14th century CE survey– the Sarva-darśana-saṃgraha (“A Review of all Systems of Philosophy”) – of all the world views prevalent in southern India at the time lists the Pāṇinīya system as one of sixteen, alongside Buddhism, Jainism, Vedanta, etc.[99]
Systems thinking – the drive to understand the underlying grammar of a world, of an organism or a political hierarchy – is thus embedded deeply in the Indian mindset. Fritz Staal observed, “What the mathematician Euclid is to the West, the Sanskrit linguist Pāṇini is to India, and just as the form of Western thought is often mathematical, the form of Indian thought is often linguistic.”[100] Thus the construction of the worldviews in all the Indian schools of philosophy is largely grammatical and systems-oriented as well, based on decomposition and synthesis. From this urge to decompose and classify also comes – I think – the old Indian obsession with enumeration of types and sub-types and sub-sub-types; so a poet-scholar in the 16th century CE listed sixteen types of nāyikas, romantic heroines, and then added, “Each of the sixteen types of nāyikas described so far can be further subdivided into eight sorts: the woman whose lover is away on travels, the woman whose lover has cheated on her, the woman separated from her lover by a quarrel, the jilted woman, the worried woman, the woman preparing for the occasion, the woman whose lover is under her thumb, and the woman who goes on a secret rendezvous. This makes 128 types. All these can be further distinguished excellent, average, and low, which thus gives 384 types.”[101]
To understand anything, you need to know its ontologies and its grammar. So we might recognize, with Louis Renou, “Adhérer à la pensée indienne, c’est d’abord penser en grammairien – To adhere to Indian thought means first of all to think like a grammarian.”[102] And as the famous Sanskrit saying has it, prathame vidvāmsāh vaiyākarāṇāh, “The scholars of the first order are grammarians.”
*
Of Pāṇini, that most excellent of grammarians, we know very little. In the pre-modern Indian scientific and literary world, the emphasis was always on the work, not on the creators. Authors might express their gratitude to their teachers at the beginning or end of a book, and perhaps mention their parents, but to include a biographical note would have been considered very bad form, quite unthinkable. The Indian corpus of pre-modern manuscripts is enormous, and scholars cite figures that are almost unbelievable – a conservative estimate is seven million complete books, and the “late Prof. David Pingree, basing his count on a lifetime of academic engagement with Indian manuscripts, estimated that there were thirty million manuscripts, if one counted both those in public and government libraries, and those in private collections.”[103] But the tradition, for the most part, did not consider personal papers and suchlike worth preserving, so we have no letters from Pāṇini, no reminiscences from his students. What we have are passing mentions of the person in scholarly works, and legend.
Patañjali, who lived maybe three centuries after Pāṇini, describes him as analpamatiḥ, “infinitely intelligent.”[104] The Chinese Buddhist monk Xuánzàng (Hsüan-tsang), who travelled and studied in India during the 7th century CE, writes in his autobiography that when he reached a place called So-lo-tu-lu in the northwest of the country he was told that it was the birthplace of the famous sage Pāṇini, who had been “from his birth extensively informed about things (men and things).”[105] Xuánzàng was also told about another long-ago Buddhist traveller who had arrived in this town five hundred years after the death of the Buddha, and was then told by a local brahmin that “The children of this town, who are his [Pāṇini’s] disciples, revere his eminent qualities, and a statue erected to his memory still exists.”[106]
In a copper plate inscription from the 7th century CE, Pāṇini is referred to as Śālāturiya, “man from Śālātura.”[107] This place is identified with a site near modern-day Lahur, a village now in north-west Pakistan, a few miles from the ancient university at Takṣaśilā (called Taxila by the Greeks who settled in the region after Alexander’s invasion). Pāṇini mentions Takṣaśilā in the Aṣṭādhyāyi and is said to have been associated with the academic institution.[108]
In his Great Commentary, Patañjali paints a beautiful picture of Pāṇini as teacher, while also paying homage to the economy of the Aṣṭādhyāyī: “The respected teacher functioning as the authority, holding the purifying bunch of darbha grass in his hands, having seated on a clean ground and his face facing the East used to formulate sūtras with great effort. This being so, it is impossible for a single sound (in his sūtra) to be useless.”[109]
And, according to legend, it is while teaching that the great sage met his end: he was sitting with his pupils, and a lion roared nearby. Instead of running away, Pāṇini started contemplating the tonal qualities of the lion’s roar. Then, as the Paṇcatantra memorably puts it, siṃhō vyākaraṇasya karturaharat prāṇan munē: paṇinē (“The lion carried away the life of Sage Pāṇini, the author of grammar”).[110]
Patañjali also tells a tale that pithily captures the generosity of generational systems. Indra, the king of the gods, the ideal student, wanted to learn about language. So he asked Bṛhaspati, the lord of learning, the ideal teacher, to instruct him. Then, “Bṛhaspati proclaimed to Indra for a thousand heaven years [4,320,000 human years] a complete text of words listed individually and yet he did not get to the end.”[111] Patañjali then concludes that this method of individual enumeration, pratipada-pāṭha, is equal to no method at all; instead, a set of rules formulated with the general (sāmānya) and particular (viśeṣa) in mind would allow us to understand the enormity of language with little effort.[112]
And this is what Pāṇini did: with a small set of rules, he captured – as the saying goes – the ocean in a cow’s hoofprint.
Bibliography (Click to expand)
Allen, William Sidney. Phonetics in Ancient India. Vol. 1. Oxford University Press, 1953. Andresen, Julie Tetel. “Toward a History of American Linguistics.” Language 86, no. 1 (2010): 226–28. https://doi.org/10.1353/lan.0.0185. Beck, Guy L. Sonic Theology: Hinduism and Sacred Sound. Columbia, S.C.: University of South Carolina Press, 1993. Bhānudatta. “Bouquet of Rasa” & “River of Rasa.” Translated by Sheldon Pollock. NYU Press, 2009. Bhate, Saroja. Panini. Makers of Indian Literature. New Delhi: Sahitya Akademi, 2002. Bloomfield, Leonard. Linguistic Aspects of Science. Vol. 1. 4. University of Chicago Press, 1939. ———. “Menomini Morphophonemics.” Travaux Du Cercle Linguistique de Prague 8 (1939). Bronkhorst, Johannes. “The Relationship Between Linguistics and Other Sciences in India.” In History of the Language Sciences / Geschichte der Sprachwissenschaften / Histoire des sciences du langage, 1. Teilband, eBook-Paket 2008 HSK / eBook ... / Hand), edited by Hans-Josef Niederehe, Sylvain Auroux, and E. F. K. Koerner, Reprint 2017 ed. edition., 166–73. Berlin: De Gruyter Mouton, 2000. Cardona, George. Pāṇini: A Survey of Research. Motilal Banarsidass Publ., 1997. ———. “Studies in Indian Grammarians. I. The Method of Description Reflected in the Śivasūtras.” Transactions of the American Philosophical Society 59, no. 1 (1969): 47. Chandra, Vikram. Geek Sublime: The Beauty of Code, the Code of Beauty. Graywolf Press, 2014. Converse, Hyla Stuntz. “The Agnicayana Rite: Indigenous Origin?” History of Religions 14, no. 2 (November 1974): 81–95. https://doi.org/10.1086/462716. Daniels, Peter T. “Chomsky 1951a and Chomsky 1951b.” Chomskyan (R) Evolutions, 2010, 169. Dwivedi, Satyam. “Email from Satyam Dwivedi,” January 27, 2019. Emch, Gerard G., R. Sridharan, and M. D. Srinivas. Contributions to the History of Indian Mathematics. Springer, 2005. Emeneau, M. B. “Bloomfield and Pānini.” Language 64, no. 4 (1988): 755–60. Emeneau, Murray B. “India and Linguistics.” Journal of the American Oriental Society 75, no. 3 (1955): 145–153. Evison, Gillian. “The Sanskrit Manuscripts of Sir William Jones in the Bodleian Library.” In Sir William Jones, 1746-1794: A Commemoration, edited by William Jones, Alexander Murray, and University College (University of Oxford), 125–38. Oxford ; New York: Published on behalf of University College by Oxford University Press, 1998. Filliozat, Pierre-Sylvain. “Ancient Sanskrit Mathematics: An Oral Tradition and a Written Literature.” In History of Science, History of Text, edited by Karine Chemla, 137–57. Dordrecht: Springer Netherlands, 2005. https://doi.org/10.1007/1-4020-2321-9_7. ———. “Ellipsis, Lopa and Anuvṛtti,” n.d., 14. Fought, John G. “Leonard Bloomfield’s Linguistic Legacy: Later Uses of Some Technical Features.” Historiographia Linguistica 26, no. 3 (1999): 313–32. https://doi.org/10.1075/hl.26.3.08fou. Ganeri, Jonardon. The Lost Age of Reason: Philosophy in Early Modern India, 1450-1700. Oxford [England]; New York: Oxford University Press, 2011. Harris, Z. S. Review of Review of A Leonard Bloomfield Anthology, by Charles F. Hockett. International Journal of American Linguistics 39, no. 4 (1973): 252–55. Interview With Professor Noam Chomsky, 2013. https://www.youtube.com/watch?v=I2isewvsPiA. Isaeva, N. V. From Early Vedanta to Kashmir Shaivism: Gaudapada, Bhartrhari, and Abhinavagupta. SUNY Press, 1995. Jakobson, Roman. Phonological Studies. Walter de Gruyter, 2012. Jha, Amar Nath. “Sanskrit Grammar and Linguistics.” In Studies in ELT, Linguistics and Applied Linguistics, edited by Mohit Kumar Ray, 199–208. Atlantic Publishers & Dist, 2004. Jha, Ganganatha, and Mammaṭācārya. The Kāvyapṛakāsha of Mammaṭa. Varanasi: Bharatiya Vidya Prakashan, n.d. http://forward.library.wisconsin.edu/catalog/ocm12761995. Johnson, W. J. A Dictionary of Hinduism. 1 edition. New York, NY: OUP Oxford, 2010. Joseph, George Gheverghese. “Geometry of Vedic Altars.” In Architecture and Mathematics from Antiquity to the Future: Volume I: Antiquity to the 1500s, edited by Kim Williams and Michael J. Ostwald, 149–62. Cham: Springer International Publishing, 2015. https://doi.org/10.1007/978-3-319-00137-1_10. Joshi, S. D. “Background of the Aṣṭādhyāyī.” In Sanskrit Computational Linguistics, 1–5. Springer, 2009. http://link.springer.com/chapter/10.1007/978-3-540-93885-9_1. Kadvany, John. “Pāṇini’s Grammar and Modern Computation.” History and Philosophy of Logic 37, no. 4 (October 2016): 325–46. https://doi.org/10.1080/01445340.2015.1121439. ———. “Positional Value and Linguistic Recursion.” Journal of Indian Philosophy 35, no. 5–6 (December 2007): 487–520. https://doi.org/10.1007/s10781-007-9025-5. Kapoor, Kapil. Dimensions of Pāṇini Grammar: The Indian Grammatical System. New Delhi: D.K. Printworld, 2005. Keay, John. India: A History. Revised and Updated. Revised, Expanded edition. New York: Grove Press, 2011. Kiparsky, Paul. “Economy and the Construction of the Sivasutras.” Paṇinian Studies: Professor SD Joshi Felicitation Volume. Center for South and Southeast Asian Studies, University of Michigan, Ann Arbor, Michigan, 1991. ———. “Email from Paul Kiparsky,” June 24, 2015. ———. “Paninian Linguistics.” The Encyclopedia of Language and Linguistics 6 (1995). Koerner, E. F. K. “Remarks on the Origins of Morphophonemics in American Structuralist Linguistics.” Language & Communication 23, no. 1 (2003): 1–43. Kulkarni, Amba. “Later Nyāya Logic: Computational Aspects.” Handbook of Logical Thought in India, 2018, 1–23. ———. “Pāṇīni’s Aṣṭādhyāyī: A Computer Scientist’s Perspective.” NIAS, Bangalore, December 5, 2008. ———. “पाणिनि : An Informatician.” August 22, 2013. http://sanskrit.uohyd.ac.in/events-new/ashtadhyayi.pdf. Leeming, David. The Oxford Companion to World Mythology. Oxford University Press, USA, 2005. Mādhava. The Sarva-Darśana-Saṃgraha: Or, Review of the Different Systems of Hindu Philosophy. Translated by E. B. Cowell and A. E. Gough. K. Paul, Trench, Trübner, 1882. Manjali, Franson. “The ‘Social’ and the ‘Cognitive’ in Language: A Reading of Saussure, and Beyond,” 2012. http://hal.archives-ouvertes.fr/halshs-00724036/. Nautiyal, K. P., and B. M. Khanduri. “Excavation of Vedic Brick Altar at Purola, District Uttarakashi, Central Himalaya.” Pratattva 19 (1989): 68–69. Pāṇini. The Ashtádhyáyí of Pánini. Translated by Śriśa Chandra Vasu. Vol. 3. Allahabad: Satyajnan Chaterji at the Panini Office, 1894. “Parsing: A Timeline -- V3.1.” Accessed January 2, 2019. https://jeffreykegler.github.io/personal/timeline_v3. Penn, Gerald, and Paul Kiparsky. “On Panini and the Generative Capacity of Contextualized Replacement Systems.” In COLING (Posters), 943–950. Citeseer, 2012. Petersen, Wiebke. “How Formal Concept Lattices Solve a Problem of Ancient Linguistics.” In Conceptual Structures: Common Semantics for Sharing Knowledge, edited by Frithjof Dau, Marie-Laure Mugnier, and Gerd Stumme, 3596:337–52. Berlin, Heidelberg: Springer Berlin Heidelberg, 2005. https://doi.org/10.1007/11524564_23. Ravishankar, Chinya V. Sons of Sarasvati: Late Exemplars of the Indian Intellectual Tradition. Global Academic Publishing, 2018. Rodrigues, Hillary. Hinduism -- The EBook, 2nd Edition. Journal of Buddhist Ethics Online Books, Ltd., 2016. Rogers, David E. “The Influence of Panini on Leonard Bloomfield,” n.d., 50. Romashko, S.A. “Böhtlingk, Otto Nikolaus (1815–1904).” In Encyclopedia of Language & Linguistics, 88–89. Elsevier, 2006. https://doi.org/10.1016/B0-08-044854-2/04541-7. Sathe, Gopal. “Code For Supercomputers In Sanskrit, Says Minister Of State For Skill Development (Sigh!).” HuffPost India, June 22, 2018. https://www.huffingtonpost.in/2018/06/22/code-for-supercomputers-in-sanskrit-says-minister-of-state-for-skill-development-sigh_a_23465303/. Scharfe, Hartmut. Education in Ancient India. Leiden; Boston: Brill, 2002. http://public.eblib.com/choice/publicfullrecord.aspx?p=253527. Sharma, Rama Nath. “The Indian Tradition of Linguistics and Pāṇini,” 2006. Sharma, Rama Nath, and Pāṇini. The Aṣṭādhyāyī of Pāṇini. Vol. 1. New Delhi: Munshiram Manoharlal Publishers, 1987. Shepheard, David. “Saussure’s Vedic Anagrams.” The Modern Language Review 77, no. 3 (July 1982): 513. https://doi.org/10.2307/3728060. Shulman, David Dean. More Than Real: A History of the Imagination in South India. Cambridge, Mass.: Harvard University Press, 2012. Staal, Frits. A Reader on the Sanskrit Grammarians. Studies in Linguistics 1. Cambridge: MIT Press, 1972. ———. Exploring Mysticism: A Methodological Essay. University of California Press, 1975. Staal, Frits, C. V. Somayajipad, and M. Itti Ravi Nambudiri. Agni, the Vedic Ritual of the Fire Altar. Vol. 2. Berkeley: Asian Humanities Press, 1983. ———. Agni, the Vedic Ritual of the Fire Altar. Vol. 1. Berkeley: Asian Humanities Press, 1983. Starobinski, Jean. Words Upon Words: The Anagrams of Ferdinand De Saussure. New Haven: Yale University Press, 1979. Subbanna, Sridhar, and Shrinivasa Varakhedi. “Computational Structure of the Astadhyayi and Conflict Resolution Techniques.” In Sanskrit Computational Linguistics, 56–65. Springer, 2009. Thapar, Romila. “The Archeological Background to the Agnicayana Ritual.” In Agni, the Vedic Ritual of the Fire Altar, 2:3–40. Berkeley: Asian Humanities Press, 1983. Trautmann, Thomas R. Aryans and British India. Berkeley: University of California Press, 1997. Tull, Herman. “Whence Sanskrit? (Kutaḥ Saṃskṛtamiti): A Brief History of Sanskrit Pedagogy in the West.” International Journal of Hindu Studies 19, no. 1 (April 1, 2015): 213–56. https://doi.org/10.1007/s11407-015-9179-9. Varakhedi, Shrinivasa. “Sanskrit and Computing: Myth and Truth.” Aksharam, Bangalore, September 21, 2013. Winternitz, Maurice, and Moriz Winternitz. History of Indian Literature. Motilal Banarsidass Publ., 1985. Wright, Edmund, and John Daintith. A Dictionary of Computing. Online. Oxford University Press, 2008. http://www.oxfordreference.com/10.1093/acref/9780199234004.001.0001/acref-9780199234004-e-2050. Wujastyk, Dominik. “Indian Manuscripts.” In Manuscript Cultures: Mapping the Field, edited by Jorg B. Quenzer and Jan-ulrich Sobisch. Walter De Gruyter Inc, 2013.Notes (Click to expand)
Due to limitations of our blogging platform and lack of time, I was unable to make footnotes work in a sane manner for this post. To read with footnotes, please download a PDF copy here.To download the latest version of Granthika, click here.
